
AI 가속기(3) _ Systolic Array의 성능 개선: Loop Unrolling, Data Flow
AI 가속기(2) _ WorkloadsAI 가속기(1) _ Systolic Array대규모 딥러닝 모델의 연산 성능을 끌어올리기 위한 하드웨어 설계가 치열하게 전개되고 있습니다. 특히, Google TPU를 시작으로 각광받기 시작한 Systol
semicon-circuit.tistory.com
Systolic Array의 성능을 개선하는 방법으로 loop unrolling과 dataflow를 조정하는 것 외에도 Tiling, On-Chip Buffer과 Bandwidth 최적화를 통한 방법이 있습니다.
Array Size와 Tiling
Array Size는 Systolic Array 내부의 PE의 행 × 열 크기를 의미합니다. 즉, 얼마나 많은 PE가 한 번에 연산을 수행할 수 있는지를 결정하는 구조적 요소입니다.
일반적으로 딥러닝 연산에서의 전체 Workload는 Array Size보다 훨씬 크기 때문에, 단일 시스톨릭 어레이만으로 모든 연산을 동시에 수행하기는 어렵습니다. 즉, Systolic Array가 전체 루프를 언롤링해서 처리하기엔 크기상 한계가 존재하며, 이를 해결하기 위해 Workload를 여러 개의 작은 타일(Tile)로 분할한 후 순차적으로 처리하는 방식(Tiling)이 사용됩니다.
예를 들어, Fully Connected Layer에서 Output Feature Map(OFMAP)을 처리하는 경우, Output Stationary(OS) 데이터 흐름을 사용하는 Systolic Array는 연산 결과를 L×J개의 타일로 나누어야 정상적으로 작동합니다. 여기서 L과 J는 각각 Array의 가로(너비)와 세로(높이) 크기이며, Array Size에 따라 타일링 구조도 달라지게 됩니다.
만약 Workload가 8 × 8이고, Systolic Array가 4 × 4이면 총 64개의 연산을 4개의 Tile로 나누어 Workload 16개씩 4번 연산을 수행합니다.
Tiling은 Workload가 커지며 Systolic Array 하나로 처리가 불가능해지는 상황을 해결하고, 하드웨어의 제약 조건을 극복할 수 있다는 장점이 있습니다. 그러나 Tiling 시 Systolic Array의 작업 단위가 증가하거나 루프 구조가 변경되는 등 프로세스가 변경되고, 설계의 복잡성이 증가할 수 있다는 단점이 있습니다.
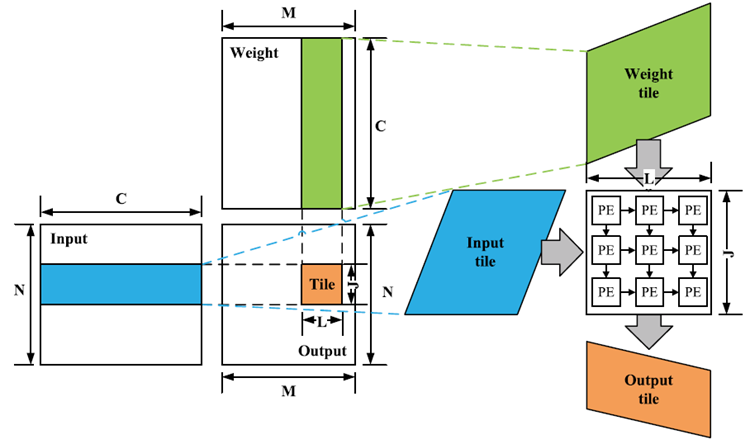
Systolic Array에서 데이터가 이동할 때, 입력 데이터와 가중치를 넣는 과정을 데이터를 채운다고 하고, 계산된 출력 데이터를 배열 밖으로 내보내는 과정은 데이터를 비운다고 합니다.
Systolic Array의 Array Size가 커지면 그 만큼 동시에 작업을 수행하는 PE 개수가 증가하여 병렬성이 증가합니다. 이에 따라 더 많은 연산이 동시에 처리된다는 장점이 있습니다. 그러나, 크기가 커진만큼 데이터의 채우기/비우기 시 데이터의 이동 시간이 증가한다는 문제가 발생합니다.
위와 같은 사항을 고려하여 설계 시 타일 크기를 설정할 때 하드웨어의 자원 제약과 데이터 흐름의 최적화를 고려하여 설계하는 것이 필요합니다.
On-Chip Buffer
Systolic Array의 성능을 좌우하는 또 하나의 핵심 요소는 바로 메모리 구조와 대역폭입니다. 특히 DNN 가속기에서 On-Chip Buffer의 크기와 Bandwidth의 크기는 연산 흐름의 연속성과 전체 처리 시간에 큰 영향을 줍니다.
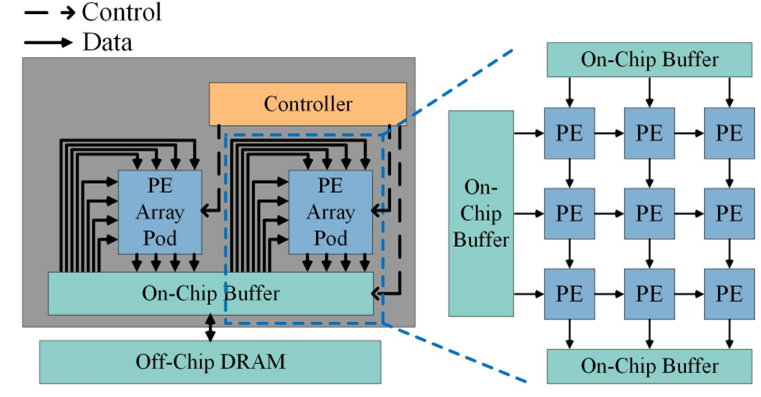
On-Chip Buffer란, Systolic Array 내부에 위치한 소형 메모리로, 연산에 필요한 입력 데이터, 가중치, 중간 출력값 등을 일시적으로 저장하는 공간입니다. 이 메모리는 연산 과정 중 Off-Chip DRAM과 같은 외부 메모리에 자주 접근하지 않도록 하여, 연산 지연과 전력 소모를 줄이는 데 핵심적인 역할을 합니다.
위와 같은 장점이 있지만, 내부의 버퍼가 너무 커지면 칩의 면적, 비용, 전력 소모가 오히려 증가할 수 있으며, 버퍼가 너무 작으면 저장공간이 부족하여 Off-Chip Memory 접근이 증가하게 되고, 이에 따라 성능이 감소할 수 있습니다.
따라서 연산 성능과 자원 효율을 동시에 고려하여 적절한 Buffer 크기를 설정하는 것이 중요합니다.
Bandwidth
Bandwidth란, On-Chip Memory ↔ Off-Chip Memory 간의 데이터 전송 속도를 의미합니다. 이를 도로에 비유하면 폭이 넓은 도로일수록 차량이 더 빨리 지나가듯, Bandwidth가 넓을수록 데이터가 빠르게 이동할 수 있습니다.

대역폭이 충분하면 연산에 필요한 데이터를 PE에 빠르게 공급할 수 있어 연산 흐름이 끊기지 않지만, 대역폭이 부족하면 데이터 공급이 지연되어 PE가 대기 상태(idle)에 빠지며 전체 성능이 저하됩니다.
다음 포스팅: Systolic Array 설계의 도전 과제
AI 가속기(5) _ Systolic Array 설계의 도전 과제
AI 가속기(4) _ Systolic Array의 성능 개선: Tiling, On-Chip Buffer, BandwidthAI 가속기(3) _ Systolic Array의 성능 개선: Loop Unrolling, Data FlowAI 가속기(1) _ Systolic Array대규모 딥러닝 모델의 연산 성능을 끌어올리기
semicon-circuit.tistory.com
'반도체 시사' 카테고리의 다른 글
| STRAIT(1) _ AI 가속기의 자가 테스트 및 복구 기술 (2) | 2025.05.05 |
|---|---|
| AI 가속기(5) _ Systolic Array 설계의 도전 과제 (1) | 2025.05.05 |
| AI 가속기(3) _ Systolic Array의 성능 개선: Loop Unrolling, Data Flow (0) | 2025.05.05 |
| AI 가속기(2) _ Workloads (0) | 2025.05.04 |