
AI 가속기(1) _ Systolic Array
대규모 딥러닝 모델의 연산 성능을 끌어올리기 위한 하드웨어 설계가 진행되고 있습니다. 특히, Google TPU를 시작으로 각광받기 시작한 Systolic Array 기반 구조는 높은 병렬성과 데이터 재사용 효율
semicon-circuit.tistory.com
지난 포스팅에 이어 이번 글에서는 Systolic Array에서 처리하는 Workload에 대해 소개합니다.
먼저, Workload란 시스템이 수행해야 하는 작업의 양 또는 작업의 유형을 의미합니다. 즉, 컴퓨터 시스템, 서버, 하드웨어 또는 AI 가속기 등이 처리하는 연산 작업의 묶음을 뜻합니다.
AI 가속기의 관점에서 Workload는 딥러닝 모델이 실제로 수행하는 연산 단위를 의미합니다. 예를 들어, Fully Connected Layer나 Convolution Layer처럼, 입력 데이터와 가중치를 기반으로 얼마나 많은 MAC(Multiply-Accumulate) 연산이 필요한지를 Workload라고 볼 수 있습니다.
이때 언급되는 레이어들은 DNN(Deep Neural Network)의 핵심 구성 요소입니다. 따라서 본격적인 설명에 앞서, 먼저 DNN 구조에 대해 간단히 짚고 넘어가겠습니다.
DNN(Deep Neural Network)
DNN은 인간의 뇌를 모방한 인공신경망의 한 형태로, 하나 이상의 은닉층(Hidden Layer)을 쌓아 복잡한 패턴 학습과 인식이 가능한 모델입니다. 최근에는 음성 인식, 이미지 분류, 자연어 처리 등 거의 모든 인공지능 분야의 핵심 기술로 자리잡고 있습니다.
DNN의 각 층은 입력 데이터에 대해 특정 수학적 연산을 수행하며, 한 층의 출력은 다음 층의 입력으로 전달됩니다. 이처럼 여러 층을 거치면서 정보를 점점 정제하고 결합해 나가면서, DNN은 데이터 속의 복잡한 패턴과 관계를 파악하고 정확한 예측 또는 분류를 수행할 수 있게 됩니다.
DNN을 구성하는 가장 작은 연산 단위는 뉴런입니다. 생물학적 뉴런과 같은 이름을 갖고 있는데, 입력을 받아 처리하고, 그 결과를 출력으로 전달하는 기능을 수행합니다. 아래 그림에서 각 파란색 원이 뉴런을 표현합니다.
DNN은 아래와 같은 3가지 층으로 구성됩니다.
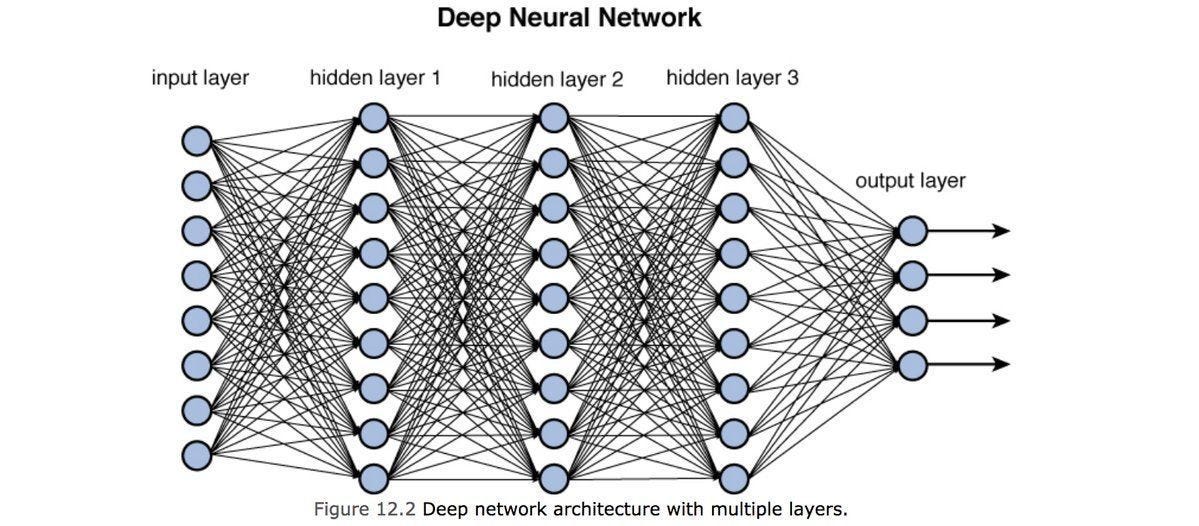
입력층
- 모델에 데이터를 입력하는 층으로, 예를 들어 이미지의 픽셀 값이나 텍스트의 단어 벡터 등이 해당됩니다.
- 입력층에서는 실제 연산은 하지 않습니다.
- ex) 28 × 28 흑백 이미지를 입력할 때, 784차원의 벡터로 평탄화하여 입력합니다.
은닉층
- 데이터의 특징을 추출하고 추상화하는 층으로, 데이터를 연산하고 가공하는 연산 중심 구간입니다.
- 각 은닉층에서는 다음의 연산을 수행합니다.
z=W⋅x+b→a=f(z)
W: 가중치 행렬
x: 이전 층의 출력
b: 편향
f: 활성화 함수(ReLU, Sigmoid 등)
- 위 연산을 반복하며 첫 번째 은닉층은 저수준 특징을 인식하고, 깊은 층으로 갈수록 고수준 추상화를 학습합니다.
출력층
- 은닉층에서 추출된 특징을 바탕으로 최종 결과를 계산합니다.
Fully Connected Layer
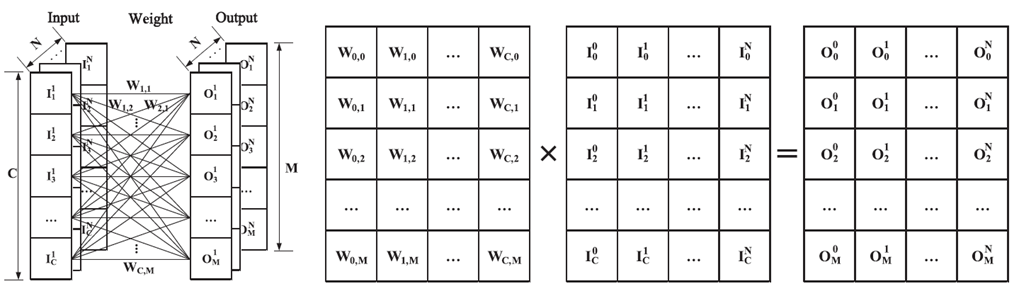
Fully Connected Layer(FC Layer)는 DNN의 Layer 종류로, 입력층의 모든 뉴런이 출력층의 모든 뉴런과 연결된 구조를 가지고 있으며, 전통적인 다층 퍼셉트론에서 사용되는 연산 방식입니다. 입력층의 모든 뉴런이 출력층의 모든 뉴런과 연결되어 있으므로 입력과 출력 간의 관계를 모두 학습할 수 있습니다.
FC Layer는 행렬 곱을 기반으로 강력한 특징의 표현이 가능하지만, 연산량과 파라미터의 수가 많다는 단점이 있습니다. Systolic Array나 GPU 등의 AI 가속기에서는 FC Layer의 행렬 연산을 하드웨어적으로 병렬화하여 처리합니다.
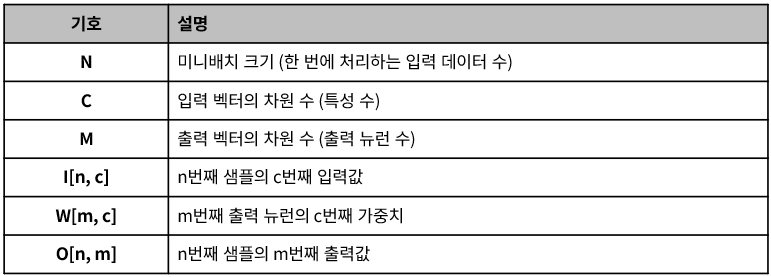
FC Layer의 알고리즘을 나타내면 다음과 같으며, 각 변수의 정의는 표를 참고하시면 됩니다.

여기서 Mini Batch는 데이터를 나누어 처리하기 위한 여러 개의 묶음을 말합니다. Mini Batch의 크기는 일반적으로 2의 제곱수로 설정되며, 하드웨어와 학습 효율성을 고려하여 크기를 선택합니다.
Convolution Layer

Convolution Layer는 DNN의 Layer 종류 중 하나로, 특히 Convolutional Neural Network(CNN)에서 핵심적으로 사용됩니다.
이 레이어는 입력 데이터에서 국소적인 패턴(예: 엣지, 질감, 형태 등)을 추출하는 데 최적화된 구조를 가지고 있으며, 주로 이미지 등의 구조적 데이터에 사용됩니다.
Convolution Layer는 Convolution Operation(합성곱 연산)을 통해 입력 데이터와 필터(또는 커널)를 반복적으로 곱하고 더하는 연산을 수행합니다. 이 과정을 통해 Feature Map(FMAP)이라 불리는 출력 결과가 생성되며, 이는 입력 데이터의 특징을 압축적으로 표현한 것입니다.
이 레이어는 CNN에서 보통 다음과 같은 특징을 학습합니다:
- 낮은 층: 이미지의 가장자리(엣지), 질감(texture)
- 깊은 층: 복잡한 모양, 객체의 형태, 위치 정보
Convolution Layer의 구성 요소
| 입력 데이터 | 일반적으로 이미지 형태이며, 다채널 구조 (예: 컬러 이미지 = RGB 3채널) |
| 커널(Filter) | 입력의 특징을 추출하기 위한 작은 가중치 행렬 (예: 3×3, 5×5 등) |
| FMAP | 커널 연산 결과로 생성된 출력, 특징 맵 |
| 채널(Channel) | FMAP의 깊이, 필터 수에 따라 달라짐 (예: 필터 64개 → 출력 채널 64개) |
| 스트라이드(Stride) | 커널이 입력 위를 이동하는 간격 |
| 패딩(Padding) | 입력 테두리 처리 방식 (예: SAME, VALID) |
Convolution Layer 연산
Convolution Layer의 연산 과정을 자세히 살펴보면 다음과 같습니다.
1. 작은 커널이 입력 데이터 위를 슬라이딩하며 이동합니다.
2. 각 위치마다 커널과 입력 데이터를 곱한 뒤 합산합니다.
3. 이 결과를 출력의 해당 위치에 저장합니다.
4. 위 과정을 반복하며 FMAP이 생성됩니다.
Convolution Layer의 Workload
Convolution Layer는 지역적 특징 추출에 특화되어 있어 FC Layer보다 적은 파라미터로도 높은 성능을 낼 수 있지만, 연산량 자체는 매우 큽니다. 그러나 병렬 처리에 유리하여 Systolic Array나 GPU 등의 하드웨어 가속기에서 효과적으로 처리됩니다.

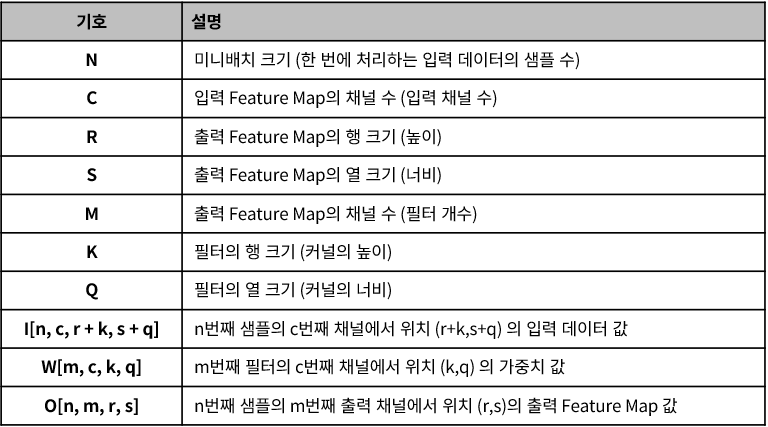
Convolution Layer의 알고리즘을 나타내면 다음과 같으며, 각 변수의 정의는 표를 참고하시면 됩니다.

다음 포스팅: Systolic Array에서의 성능 개선 방안_Loop Unrolling과 Data Flow
AI 가속기(3) _ Systolic Array의 성능 개선: Loop Unrolling, Data Flow
AI 가속기(2) _ WorkloadsAI 가속기(1) _ Systolic Array대규모 딥러닝 모델의 연산 성능을 끌어올리기 위한 하드웨어 설계가 치열하게 전개되고 있습니다. 특히, Google TPU를 시작으로 각광받기 시작한 Systol
semicon-circuit.tistory.com
'반도체 시사' 카테고리의 다른 글
| AI 가속기(4) _ Systolic Array의 성능 개선: Tiling, On-Chip Buffer, Bandwidth (0) | 2025.05.05 |
|---|---|
| AI 가속기(3) _ Systolic Array의 성능 개선: Loop Unrolling, Data Flow (0) | 2025.05.05 |
| AI 가속기(1) _ Systolic Array (1) | 2025.05.04 |
| 4th SSA: AI, AI Semiconductor (1) _ AI 기술의 현재, 미래 (0) | 2025.02.26 |